Why Zero Knowledge Proofs Matter
At a high level, proving works by turning trust into mathematics: instead of "trust me, I did some calculations correctly," the prover generates a proof that can be efficiently verified. This is the core idea behind delegated computation, which we introduced in this article.
By leveraging ZK protocols and techniques, a system can be designed such that the verifier does not have to redo all the calculations, which makes verification significantly cheaper.
But why does this actually matter in practice?
In blockchain systems, computation is constrained by limited on-chain resources. As dApps grow in scope, they require increasingly sophisticated execution, which quickly runs into these limits. This becomes especially clear in perpetual markets, where flows are both demanding and latency-sensitive. Matching, liquidations, and risk checks must run continuously on a rapidly changing state, and even small inefficiencies can directly impact pricing and determinism.
The result is that complex dApps with real-time, state-intensive requirements can hit these walls when competing for shared blockspace, even on high-performance chains like Solana - a dynamic we covered in our article on transaction ordering. To address this, we're building a network extension model that introduces a dedicated execution environment purpose-built for perps, while liquidity, assets, and settlement stay on Solana: leveraging ZK, transactions are executed off-chain - inside the Parasol engine - and the resulting state is then verified on-chain to ensure it was computed correctly.
In this article, we break down how zkVMs work, and how they enable offloading execution while preserving verifiable correctness on-chain.
Circuits
To prove that some calculations were done correctly, cryptographers design “circuits”, which are, at a high level, a way of enforcing the properties the prover wants to convince the verifier about. Because circuits come from specialized mathematical techniques, they differ significantly from traditional programming.
Here are four key facts:
1. They are similar to “boolean circuits” in that they are not sequential. Writing circuits by hand is closer to designing an integrated circuit, like an ASIC. Here you can see an example of a boolean circuit:
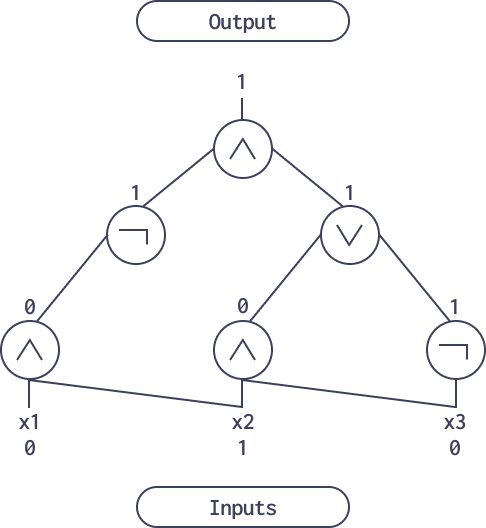
2. In some sense, they resemble Nondeterministic Turing Machines, because they can accept additional “secret witness input” that helps formulate the proved statement in a more optimal way. The process of computing these so-called “hints” does not need to be verified.
3. For example, to prove computation of a square root modulo some number, you do not need to prove how the square root was found. You provide it as a witness and prove that squaring it yields the input.
4. They work over a mathematical object called finite fields, which is, to put it simply, arithmetic modulo a large prime number. As a result, representing arithmetic operations (addition and multiplication) in circuits is much easier than, for example, bitwise AND and OR.
5. They can use additional techniques, like lookup argument. The idea is that there are protocols which allow checking if a value is an element of some set (which can be static or dynamic).
For a deeper dive into circuits, polynomial representations, and commitment schemes, see “Why ZK Isn’t Really About Zero Knowledge” - Part I and Part II.
What zkVMs Are
n the plain circuit approach, researchers design a custom circuit for each statement they need to prove. Proving a circuit can be fast with the right tricks (including cleverly using the lookup argument), but designing them takes significant effort (remember the ASIC analogy). Auditing circuits is also much harder than auditing programs.
zkVMs provide a different approach. Instead of writing a custom circuit for every application, you prove the execution of a program running on a verifiable virtual machine. The instruction set (ISA) is fixed, and the program changes. That is why using zkVMs feels much more like traditional software engineering. You compile code, run it, and prove that it executed correctly. With an ISA like RISC-V, existing code in Rust, C++, or other compiled programming languages can be reused directly, or with fairly small changes, while still using the same compiler.
Typical zkVM Architecture
The common pipeline looks like this:
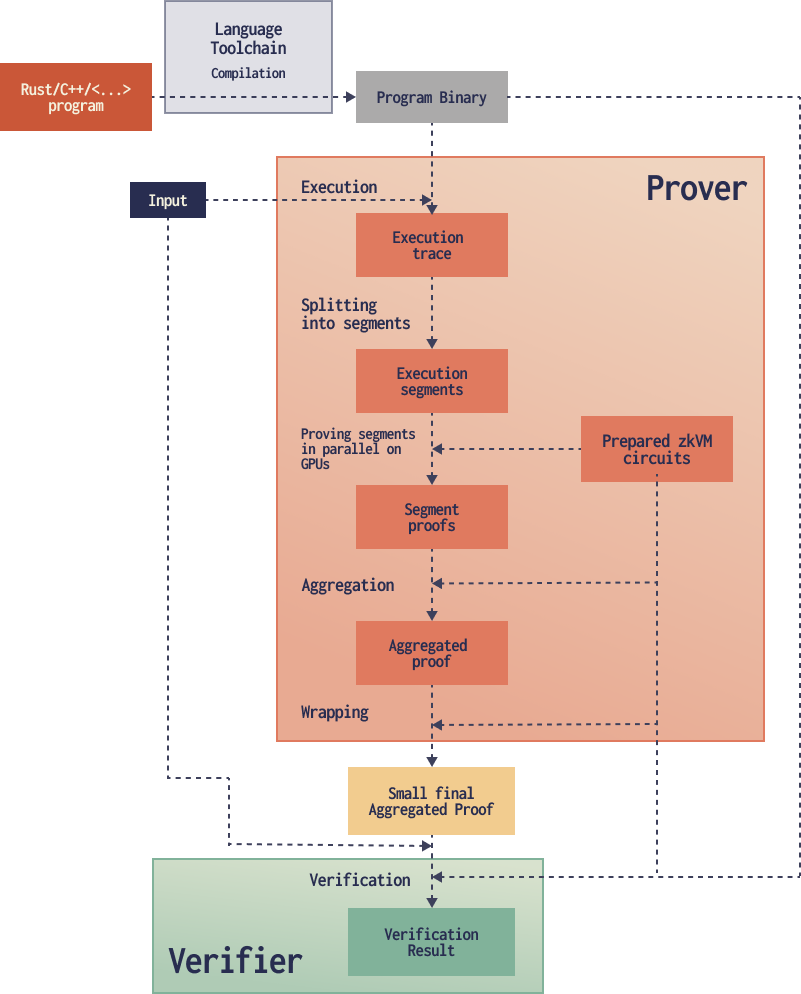
- Compiling the program
- Running the program, recording enough information to later prove the execution
- Splitting the work into manageable pieces (segments)
- Proving those segments
- Combining the segment proofs
- Optionally adding one last wrapping step so verification is even cheaper in the target environment, especially on-chain
- Verifying the final proof on-chain or locally
Below, we go through each of these steps.
Compiling the Program
It all starts with your code. You would need a slightly modified toolchain, and some additional configuration for your zkVM. After compiling, you get a binary similar to normal compilation.
At this stage, you normally get two “commitments” (hashes): the VM configuration commitment and the program commitment. The verifier will need this to verify the proofs.
Now, each time you want to prove that you correctly executed the program on some input, you run the prover.
Running the Program
The prover starts by running the program. It records some additional information like memory accesses, instructions executed, and other metadata. This is needed to fill the circuits layer. All this data combined is called the execution trace. Since the process is sequential, it cannot be parallelized (unlike proving). It is not as slow as (sequential) proving, but still slower than just executing the native code. This is why this area is currently an active field of optimization research, like using AOT (ahead-of-time) compilation to a native ISA.
Splitting the Execution into Segments
The execution trace is split into portions called segments.
This solves several problems at once:
- It bounds prover memory and runtime per each segment. This is important because the proving is normally done on GPUs which have limited vRAM.
- It enables parallel proving of independent segments. Since all segments are proved in parallel, the total proving time depends only on the time needed to prove a single segment, as long as there are enough computing resources (machines, GPUs, etc.).
- It makes very long computations possible. Each circuit is actually limited in size due to mathematical reasons, but with segmented execution the end user doesn’t need to think about this.
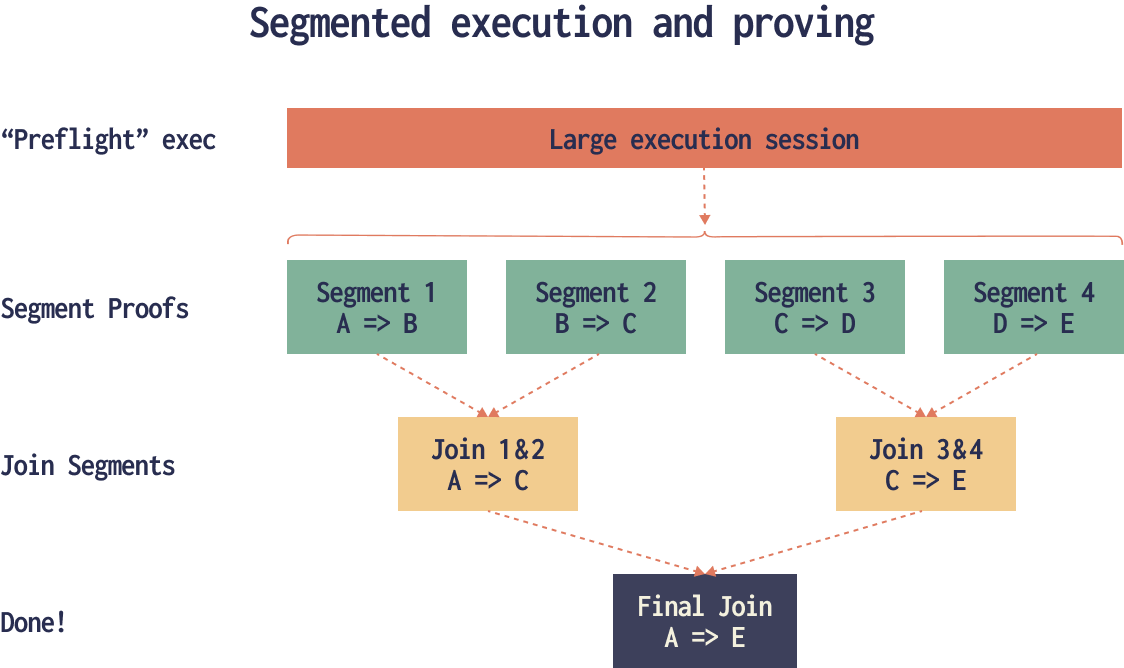
Proving the Segments
Here each segment is fed into the proving system. The circuits in this proving system are fixed and can be optimized with GPU acceleration. Since segments are independent, this step can be distributed across multiple GPUs or even across machines in a cluster.
This is mostly done using STARK proofs, which are based on the FRI protocol - we covered the underlying commitment scheme mechanics in this blog post. Interconnections between circuits are done using the lookup argument. The same lookup argument is used to prove that all the memory accesses and modifications are consistent. Additionally, special circuits ensure that the memory operations remain consistent across different segments.
Combining the Segment Proofs
Segment proofs can be combined into a single one using various techniques, most commonly recursive proving. Basically, you prove the execution of the verifier itself - actually across multiple runs - and obtain one final proof.
Here, again, the same STARK protocols are used as in the previous step.
This phase can be sped up using parallelization if the proofs are aggregated in a tree structure: instead of combining proofs one by one, they are combined in pairs, then combined again in pairs, and so on, until only one proof remains. On each layer, the combining process can be parallelized.
Final Wrapping
At this point, the proof you get from aggregation is in a format that is not practical to verify on-chain. While possible in some circumstances, verification would be quite costly. So, you wrap the proof one more time in a different proof system where proofs are smaller and verification is simpler and faster.
For this step, the most used proof systems are PLONK and Groth16, often referred to as SNARKS, because they produce the smallest proofs. We’ve written more about this approach here.
The downside is that this final step adds additional latency. These SNARKs are also not post-quantum secure. Groth16 is somewhat faster to prove than PLONK, but requires a special trusted setup ceremony for every circuit change.
Verification
The proof is then verified using commitments to the program, the zkVM configuration (known to the verifier), and the specific input. The variable parts, such as the input, are supplied as part of the proof.
In the end, the verifier obtains a verdict. Using this result, it can record that, for example, all the changes to the global state mentioned in the input are correct (such as new account balances).
Accelerating zkVMs With Precompiles
This is what makes the zkVM approach faster in practice.
Pure CPU emulation is rarely enough. Practical systems add fast paths (precompiles) using custom circuits for common heavy operations: hashing (SHA256, etc.), big integer arithmetic, and elliptic curve operations. The VM gives you flexibility, precompiles claw back performance where it matters most.
In the code, it looks as easy as just calling a function. You can think of this as doing a syscall, or invoking a special CPU instruction. In this sense, it is similar to special instruction set extensions in real CPUs, such as those for SHA256 hashing in x86. Unlike real CPUs, however, you don’t need to have a factory to produce a new CPU with your extension, so it’s easier to create new extensions from scratch. While you do need to write the circuits explicitly for each extension, this is only required for some well-defined parts of functionality, not for all general computations.
In most cases, you do not need to modify all dependencies to take advantage of this acceleration. You only modify the ones implementing the heavy operations and make every dependency use the patched version. This works well because the foundational libraries for hashing and other operations have a fairly stable API, and all the algorithms themselves are standardized.
Using Nondeterminism
The nondeterministic capabilities of circuits can be exposed to zkVM programs through a convenient interface, enabling optimization possibilities.
From a code perspective, obtaining hints can be as simple as marking certain sections as excluded from the proving procedure. This way, both the provable code and the hint source use the same familiar programming language.
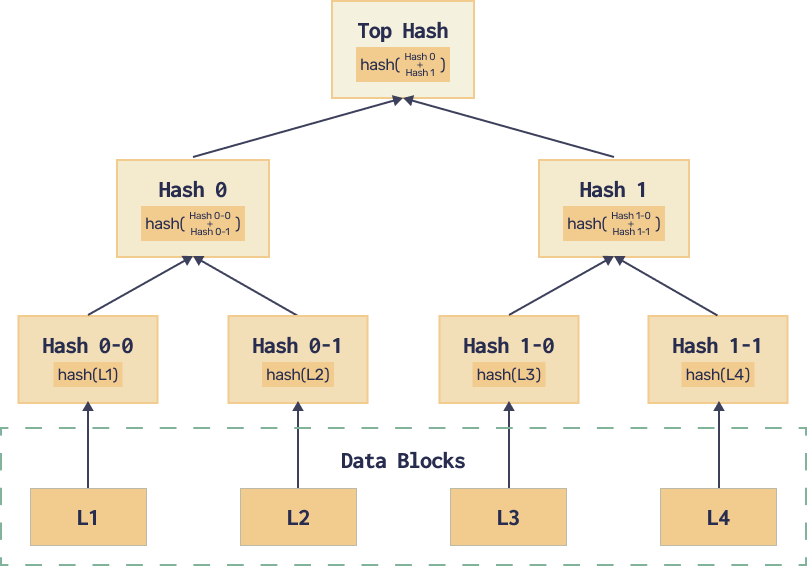
This comes in handy when implementing a data structure called Merkle tree: a way to commit to some data (hash it), and then update the hash efficiently when you change some portion of the data. It also allows checking that some part of the data is consistent with the commitment without hashing the entire dataset. The intermediary hashes can be supplied using hints instead of being part of the input.
The Downsides
The biggest problem is that the CPU abstraction adds overhead. General-purpose execution is more expensive to prove than a circuit tailored to one specific job. Keeping track of memory values adds additional complexity, whereas in plain circuits, cells used for operation results are static and native.
However, precompiles address this issue effectively. It is similar to writing logic in Python while doing the more demanding operations in native code. This reduces the path to MVP and enables faster prototyping.
Conclusion
zkVM is a very powerful abstraction that makes proving systems more practical.
Its pros include:
- Reusing existing software. You often start iterating from real programs rather than writing circuits from scratch, and you can reuse your language's package ecosystem.
- Handling long or unbounded computations thanks to segmentation.
- Proving parallelization. The same segmentation architecture enables very high proving parallelization.
- Auditing the circuits only once. The circuits are reused across many applications instead of being rebuilt for each one.
- Fast prototyping with optimization possibilities. You can start with the generic VM path, make a correct proof, and then speed up hotspots later with precompiles.
At Parasol, we're applying this approach to unlock a new class of perpetuals, where performance and market structure can evolve natively on Solana, without introducing fragmentation or sacrificing trust and composability.
Follow @buildonparasol on X to stay up to date.