In Part 1 of this article, we went over some of the shortcomings of current zkVM solutions for our setting, in particular in the context of proving EdDSA verification.
One important problem that we discussed is that the proof systems underlying zkVMs impose restrictions on the field used. This prevented us from proving EdDSA verification arithmetic natively, resulting in a significant proof generation overhead.
In practice, this overhead becomes the main bottleneck when scaling transaction proving in Parasol, where signature verification dominates.
In this article, we take a look at a family of proof systems that are field-agnostic, i.e. they can be instantiated over essentially any field. This allows us to move away from mismatched arithmetic and design solutions that better align with the actual computation performed inside the engine.
Where the problem actually lies
Recall that a proof system is very often constructed by combining **a polynomial IOP** and a polynomial commitment scheme (PCS), and then applying the Fiat–Shamir transformation. Polynomial IOPs can be built with very mild conditions, but it is the PCS that imposes the most restrictions.
- KZG requires a pairing-friendly elliptic curve, which is a strong restriction.
- FRI requires a prime field $\mathbb{F}_{p}$ where a large power of $2$ divides $p-1$ or $p + 1$. This is also not the case for most primes $p$.
So if the PCS is the problem, we just need to replace it with a different PCS that works over any field, while keeping the rest of the construction the same. The scheme that we will describe has been used in different constructions, like Bootle et al., Ligero, and Brakedown.
A first attempt at a field-agnostic PCS
Suppose that a prover wants to commit to a polynomial $f$ of degree $<D$.
We will assume that $D=d^2$ for some integer $d$. We start by arranging the coefficients of $f$ in a square matrix $F$, so that, given an evaluation point $x \in \mathbb{F}$, we have
$$\displaystyle f(x) = \underbrace{(1, x, x^2, \dots, x^{d-1})}_{L(x)^\top} \underbrace{\begin{pmatrix} f_{0,0} & \dots & f_{0,d-1} \\ \vdots & & \vdots \\ f_{d-1,0} & \dots & f_{d-1,d-1} \end{pmatrix}}_{F} \underbrace{\begin{pmatrix} 1 \\ x^d \\ x^{2d} \\ \vdots \\ x^{D-d} \end{pmatrix}}_{R(x)}$$
We first present an insecure version of the protocol, which we will later modify to achieve a sound PCS.
- To further simplify the protocol, we will assume that the evaluation point $x$ is random. This is not a limitation for us, as typically polynomial IOPs query polynomials at random points.
- Also for simplicity, we present the protocol as an IOP, which can then be compiled into an interactive proof with Merkle tree commitments. Thus, we assume that the prover can send an oracle to $F$, and the verifier can interactively query the oracle to obtain columns of $F$ at no cost.
Consider the following strategy between the prover (P) and verifier (V), in which P is trying to prove that $f(x) = y$.
- P sends an oracle to the columns of $F$.
- P sends a partial evaluation $\ell = L(x)^\top F$.
- V checks that this partial evaluation was honestly computed.
- V finishes computing $y$ themselves as $y = \ell \cdot R(x)$.
If done correctly, the verifier deals only with operations that depend linearly on $d = \sqrt{ D }$. So this is an improvement over the naive approach of having the verifier evaluate the polynomial on their own, which would have a cost at least linear in $D$.
The only question is how to guarantee that $\ell$ was honestly computed in step 3. The idea is that V will perform "spot checks" at random entries of $\ell$, checking that these have been computed honestly.
To do so, the verifier performs the following check $t$ times:
- V picks a random column index $j$.
- V queries the oracle for $F_{j}$, the $j$-th column of $F$.
- V checks that $L(x) \cdot F_{j}$ matches the $j$-th coordinate of $\ell$.
The issue with this approach is the following: how many columns does the verifier need to check to ensure that the prover is not cheating?
Suppose that the prover lies about $\ell$ at a single coefficient. Then, even if the verifier checks all the columns except for one ($t = d-1$), there is a $\frac{1}{d}$ probability of not catching the lie. We cannot accept a proof system in which the prover can cheat with non-negligible probability.
Without codes
One cell is a lie. Most spot checks miss it.

3 spot checks - none land on the lie.
Therefore, for the above to work, we would need to check all the columns. But at this point, the verifier is just performing the whole computation $L(x)^\top F$, which requires $O(D)$ operations. So the PCS is no longer succinct.
Fixing the scheme with linear codes
The idea above can still be saved with some changes. Specifically, we will modify the scheme so that the verifier can get a high guarantee of the correctness of the partial evaluation $\ell$, without resorting to checking all columns, i.e. keeping $t$ small enough.
The underlying problem above is that the prover could lie about a single location of $\ell$, so we need to check them all to ensure that they are being honest.
In this case, the prover has a $\frac{1}{2}$ probability of passing a single spot check. And more generally, they have a $\frac{1}{2^t}$ probability of passing $t$ random spot checks.
Note that this probability shrinks exponentially in $t$, so a reasonably small number of spot checks (e.g. $t = 128$) suffices to guarantee with overwhelming probability that the prover is not cheating. This is much smaller than $d$, which could easily be in the range $2^{10}$ to $2^{15}$ in practice.
So now the question becomes this: how can we ensure that the prover is forced to either behave honestly, or lie at many locations, with no situation in-between? The answer is linear codes.
A code is a mathematical construction that takes a message (you can think of the message as a vector over a finite field $\mathbb{F}$) and adds redundancy to it, in a process known as encoding. The result is known as a codeword.
A code is linear if its encoding function $\mathsf{Enc}$ is linear, i.e.
$$\mathsf{Enc}(ax + by) = a\mathsf{Enc}(x) + b\mathsf{Enc}(y),$$
for all messages $x, y$ and all scalars $a, b$. That is, a linear combination of codewords is also a codeword.
A nice property of codes is that their redundancy takes messages "further apart". Let us go over a very simple toy example first:
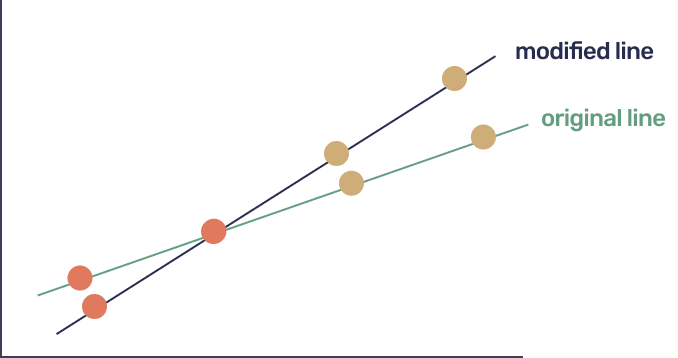
This simple code illustrates the notion of distance amplification: if two messages differ on a single point, the line will be completely different, so the corresponding codeword will differ at three points. This sounds similar to our goal of amplifying "lying at one point" to "lying at many points".
In practice, the codes that we will use are more complicated than this example, but the intuitive idea is the same. Let us see how we can apply it to fix the flawed protocol above.
We start by adding a new step at the beginning of the protocol

How does this change things with respect to the previous version? We give a very informal intuition on why this is now secure.
Essentially, the prover can cheat in two ways:
- By providing a matrix $E$ whose rows are far from codewords.
- By sending a partial evaluation $\ell'$ that does not match the honest one $\ell$.
For the first case, we will use another interesting property of linear codes: if even just one of the rows is far from the code (meaning it disagrees with the closest codeword in many positions), then the result of the random linear combination will also be far from the code.
Observe that $L(x) \cdot E_{j}$ is a random linear combination of the rows of $E$. Therefore, if the prover lies about $E$, then $L(x) \cdot E_{j}$ (not a codeword) will disagree with $e$ (a codeword) in many positions. Thus, the spot checks will easily catch the discrepancy.
For the second case, note that the honest $\ell$ is a linear combination of the rows of $F$, with scalars $L(x)$. Therefore, by the linearity of the code, $e = \mathsf{Enc}(\ell)$ is a linear combination of the rows of $E$.
If the prover tries to lie about $\ell$ and sends a different partial evaluation $\ell'$, the verifier will end up with a different codeword $e' = \mathsf{Enc}(\ell')$.
Here, an important property is that codewords differ at many locations. Unlike messages, which can differ at a single position, codewords of a well-chosen code will differ at a $\delta$-fraction of the locations, at least. This means that each spot check, comparing $L(x) \cdot E_{j}$ to the $j$-th coordinate of $e'$, will only fool the verifier with probability at most $1 - \delta$.
Without codes
One cell is a lie. Most spot checks miss it.
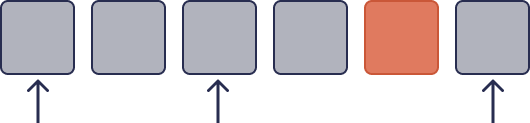
3 spot checks - none land on the lie.
With linear codes
The same lie is forced to spread across many cells.

3 spot checks - likely to land on a corrupted cell.
Thus, with $t$ random spot checks, the prover's cheating probability is reduced to $(1 - \delta)^t$, which, as discussed above, can be made exponentially small for a reasonable choice of $t$. Thus, we achieve a PCS in which the verifier work is $O(t \sqrt{ D })$ operations, which is still much better than the naive $O(D)$.
Codes and comparisons
Something we have not discussed is how to construct codes with good properties. The details of these are quite intricate, and beyond the scope of this high-level exposition. So for now, we mention an example from the Brakedown paper, which introduced a code with $\delta \approx 0.05$ and takes around $15n$ operations to encode a message of size $n$.
In contrast, Reed–Solomon codes, mentioned above and used in FRI, can achieve much larger distances (which allow us to choose smaller $t$, thus reducing the size of the proof). However, as we have already discussed, these codes only work efficiently on specific fields, whereas the Brakedown code is field-agnostic, and thus suitable for our setting. The smaller distance and bigger proofs are the price we have to pay for the field flexibility.
On the upside, an additional benefit of the Brakedown code with respect to Reed–Solomon is that the former has a faster encoding (strictly linear time), as opposed to the quasi-linear encoding of the latter. This is also a nice property which enables even faster proof generation.
Final thoughts
We have presented a field-agnostic polynomial commitment scheme, which allows us to instantiate proof systems over essentially any field. In particular, this allows us to prove EdDSA verification arithmetic without resorting to non-native arithmetic.
More importantly, this changes how we approach proof system design in our setting. Instead of adapting the computation to fit the proof system, we can design the proof system around the computation itself.
This shift is key when dealing with structured, high-throughput workloads like those in perpetual markets, where performance depends on how well the proof system matches the underlying logic.
This brings us one step closer to scaling Solana execution with Parasol.